In 2014, many teams said, “I do not need containers. My virtual machines work fine.”
They were right.
Virtual machines did work. Deployment scripts did work. A few careful engineers could keep the machinery moving.
Then Docker changed the unit of software delivery. It did not make infrastructure obsolete. It made environments repeatable, portable, and composable. The shift was not only technical. It changed how teams thought about shipping, testing, scaling, and owning software.
AI agents are approaching a similar inflection point.
For the last two years, the conversation has been dominated by models: which LLM is best, which benchmark matters, which context window is bigger.
Those questions still matter.
But the more important production question is now:
What are we building around agents so they can be trusted with real work?
From Experiments To Systems
The first generation of AI agents was exciting and fragile in equal measure.
Wire a model to a few tools, let it browse a page, edit a file, run a command, and you had something that felt like magic.
It was also incomplete.
“It works in the demo” is not the same as “it works in production.”
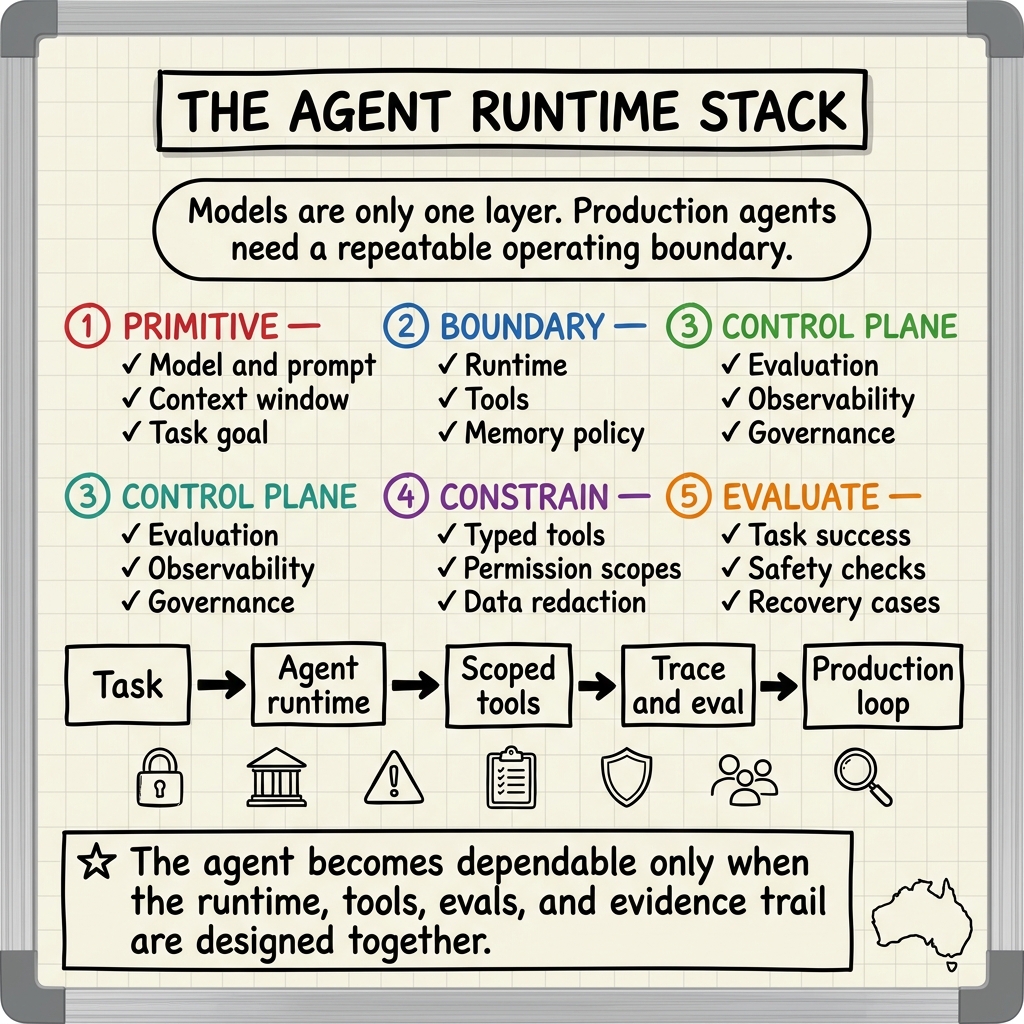
Production systems need more than capability. They need repeatability, permission boundaries, failure handling, memory constraints, test coverage, audit trails, and clear ownership.
That is where the agent ecosystem is now building.
| Infrastructure layer | Why agents need it |
|---|---|
| Runtime | Defines where the agent runs, what state it has, and what environment it can touch. |
| Tool boundary | Controls which APIs, files, browsers, and systems the agent can access. |
| Memory policy | Decides what the agent can remember, retrieve, forget, or expose. |
| Evaluation | Tests task success, safety, consistency, tool use, cost, and recovery. |
| Observability | Records decisions, tool calls, evidence, approvals, and failures. |
| Governance | Sets approval gates, permissions, data rules, and accountability paths. |
The interesting engineering is no longer only inside the model.
It is in the layers around it.
Why The Docker Comparison Holds
The comparison is not perfect, but it is useful.
Docker gave teams a reliable boundary around software processes. Before it, every team had its own answer to basic questions:
- What exactly is running in production?
- What dependencies does it need?
- Can we reproduce staging locally?
- How do we package and deploy this consistently?
- How do we scale it without inventing a new ritual each time?
AI agents need the same class of answers.
When an agent changes code, drafts a customer response, browses the web, approves a workflow, or calls an internal API, the organisation needs to know what happened and why.
The model response is only part of the story.
The surrounding system determines whether the agent is trustworthy.
The Mental Model Shift
Stop thinking of an agent as “a model with tools.”
Start thinking of it as a workload that needs a runtime.
| Layer | Containers | Agents |
|---|---|---|
| Core primitive | Application code | Model, prompt, context, and task |
| Capability | Libraries and APIs | Tools, APIs, browsers, files, and workspaces |
| Runtime | Container engine | Agent harness and execution environment |
| Orchestration | Compose, Kubernetes, workflows | Multi-agent coordination and durable task flows |
| Quality gate | CI, tests, deployment checks | Evals, safety tests, consistency checks |
| Observability | Logs, traces, metrics | Decision traces, tool-call audits, evidence trails |
| Governance | IAM, network policy, runtime security | Permission scopes, approval gates, data controls |
A container runtime does not make code smarter.
It makes code easier to run, move, inspect, and recover.
Agent infrastructure should do the same for agentic work.
What Developers Should Build For
Four capabilities separate agent workflows that can be trusted from ones that merely look impressive.
1. Reproducible Runs
A serious agent workflow should be inspectable and replayable.
This does not mean making LLM output perfectly deterministic. That is not realistic. It means the system captures enough context to debug failures, compare runs, and improve behaviour over time.
At minimum, capture:
- user goal
- prompt and system instructions
- model version
- tool permissions
- tool calls and results
- files or records touched
- human approvals
- final output
- cost, latency, and error states
If you cannot reconstruct the path, you cannot learn from it.
2. Tool Boundaries And Permission Scopes
The best agents are not the ones with unlimited access.
They are the ones with the right access at the right time.
“Can call tools” is not a policy.
The real questions are:
- Which tools?
- Against which data?
- Under which conditions?
- With what approval gate?
- With what rollback path?
- With what audit trail?
Permission scopes, secret handling, data redaction, and human override paths are what make an agent safe enough to put near production systems.
3. Evaluation As A Deployment Gate
Unit tests are not enough for agentic systems, but the principle still applies: no serious team ships blind.
Agent evals should test:
| Evaluation area | What to check |
|---|---|
| Task success | Did the agent complete the intended job? |
| Tool correctness | Did it call the right tool with the right arguments? |
| Safety | Did it refuse unsafe, unauthorised, or policy-breaking actions? |
| Recovery | Did it handle partial failure without making things worse? |
| Cost and latency | Did it complete within an acceptable operating budget? |
| Consistency | Does it behave acceptably across repeated runs and edge cases? |
The best teams treat eval suites the way mature teams treat CI.
They run before deployment. They block risky changes. They improve after incidents.
4. Observability For Decisions
Traditional logs tell you what a service did.
Agent traces need to tell you what the agent believed, what evidence it used, what it tried, which tools it called, and where a human intervened.
Without that trail, every production incident becomes a mystery.
With that trail, every incident becomes training data for a better system.
What Leaders Should Decide Now
For technology leaders, the agent shift is strategic.
The wrong frame is:
Which model should we license?
The better frame is:
| Leadership decision | Why it matters |
|---|---|
| Which workflows are genuinely agent-shaped? | Not every automation problem needs an agent. |
| What can agents do autonomously? | Autonomy without boundaries creates operational risk. |
| What requires human approval? | Accountability must be explicit before production. |
| What platform capabilities should be centralised? | Every team should not invent its own tool gateway, memory policy, and eval harness. |
| How will quality be measured? | Agent performance needs more than demo success. |
| How will incidents be reconstructed? | Production trust requires evidence trails. |
The companies that answer these questions early will have an operating advantage.
The companies that only chase model upgrades will accumulate impressive demos and fragile workflows.
The Production-Readiness Checklist
An agent workflow is not ready for serious work until it has:
- scoped tools and permissions
- environment isolation
- secret handling and data redaction
- prompt and policy versioning
- evals for expected and unsafe behaviour
- human approval gates for high-risk actions
- traceable tool calls and evidence
- cost and latency monitoring
- incident replay
- rollback or compensation paths
- ownership across product, engineering, risk, and operations
That may sound heavy.
It is the same thing that happened with containers. The industry first celebrated the primitive, then built the operating discipline around it.
Security And Well-Architected Gaps To Call Out
Agents combine LLM risk with classic application security risk. They read untrusted content, call tools, operate on files, invoke APIs, and may act across systems.
| Gap | What it looks like | Control |
|---|---|---|
| Prompt injection through tools | A web page, document, ticket, or email tells the agent to ignore policy or exfiltrate data. | Treat all retrieved content as untrusted and separate instructions from data. |
| Over-broad tool access | The agent can read, write, delete, browse, or deploy beyond the task boundary. | Scope tools per task, require approval for risky actions, and deny by default. |
| Secret exposure | Tokens, environment variables, customer data, or internal URLs appear in prompts, traces, or outputs. | Redact secrets, isolate execution, and review what gets logged. |
| Unsafe code or command execution | The agent runs generated commands without sandboxing or review. | Use sandboxed workspaces, command allowlists, policy checks, and human approval. |
| Missing recovery path | The agent changes code, data, or configuration without rollback. | Require diffs, tests, backups, revert paths, and auditable approvals. |
The Well-Architected gaps are just as important: no clear owner, no eval gate, no operational dashboard, no cost budget, no incident replay, and no reliability target. A production agent should be reviewed like a workload, not like a chatbot.
The Moment We Are In
The AI agent story is shifting from intelligence to infrastructure.
That does not mean models stop mattering.
It means models are now one input into a broader production system.
In the container world, application code was never the only thing that mattered. The runtime, registry, orchestration layer, deployment pipeline, security model, and operating discipline were where teams separated themselves.
The same dynamic is playing out with agents.
The question is no longer only:
Which LLM is best?
The better question is:
What have we built around agents so they can do real work reliably, safely, and at scale?
That is the Docker moment.
Not because agents are containers.
Because the industry is discovering the abstraction layer that turns a powerful primitive into something organisations can actually depend on.
Sources and Further Reading
- jcode: Coding Agent Harness
- Ruflo: Agent Orchestration Platform
- webact: Browser Control for AI Agents
- Amazon Bedrock AgentCore Browser OS-level interaction announcement
- OWASP Top 10 for LLM Applications
- AWS Well-Architected Framework
Written by Haris Habib from Sydney, Australia | May 2026