Every system fails.
The real question is not if something breaks. It is whether the system fails in a way your customers, operators, and engineers can survive.
After two decades around payment systems, I have learned that the most expensive failures are not always the spectacular crashes. They are often slow degradations: queue buildup, partial dependency failure, retry storms, stale data, silent timeouts, and dashboards that look healthy while customers are already feeling pain.
Resilience engineering is the discipline of designing for those conditions before they arrive.
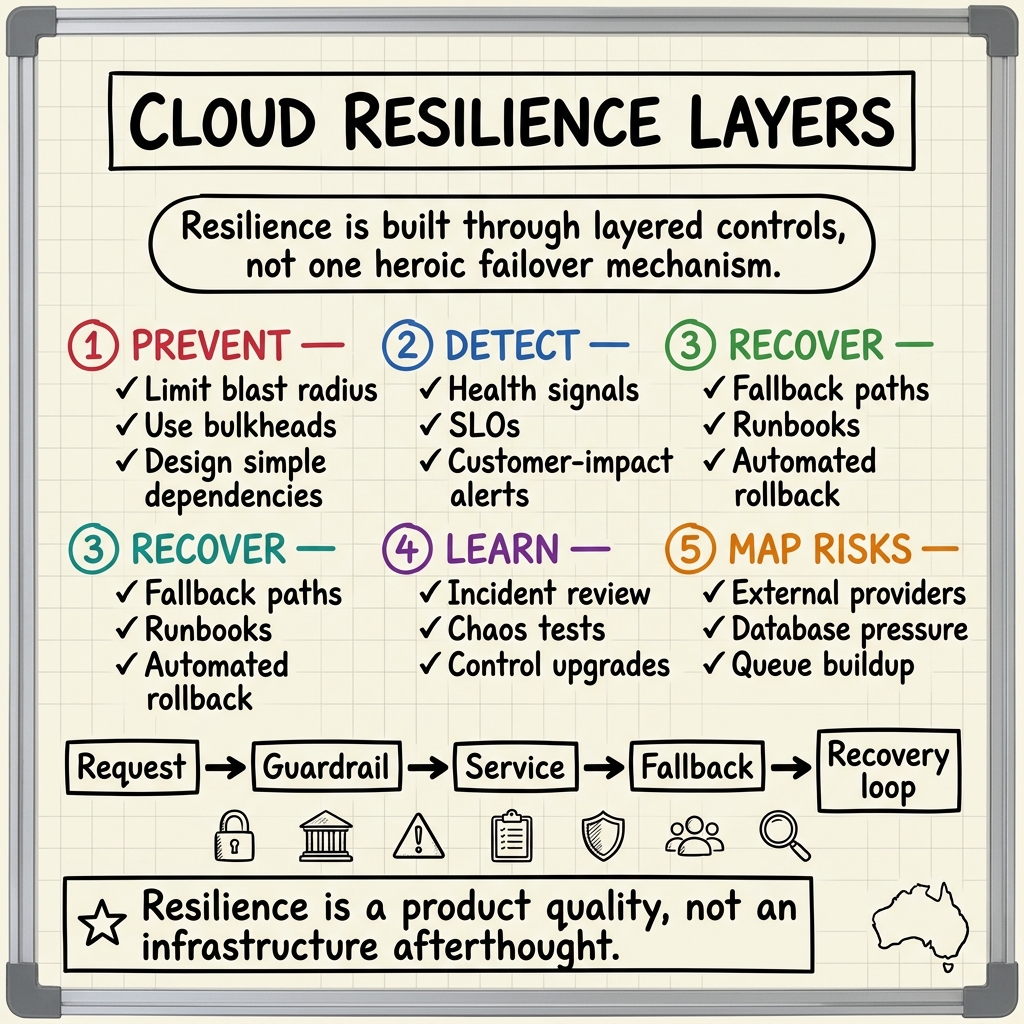
The 10-Star Resilience Test
A basic cloud system stays online on a normal day.
A strong cloud system degrades gracefully on a bad day.
A 10-star cloud system gives the team enough control, evidence, and recovery paths that a failure becomes manageable instead of mysterious.
| Resilience question | Weak answer | Strong answer |
|---|---|---|
| What can fail? | ”The cloud provider handles that.” | Failure modes are mapped by dependency, region, queue, database, and user journey. |
| How do we detect it? | ”We have CPU alerts.” | Customer-impacting SLOs, error budget signals, queue lag, saturation, and synthetic checks are monitored. |
| How do we contain it? | ”Retries will help.” | Circuit breakers, bulkheads, rate limits, and backpressure prevent cascading failure. |
| How do we recover? | ”Someone will fix it.” | Fallbacks, rollback, replay, runbooks, and automated recovery paths are tested. |
| How do we learn? | ”We do a postmortem.” | Incidents update tests, alerts, dashboards, architecture decisions, and game days. |
The Four Pillars Of Resilience
Before choosing cloud services, define the resilience shape you need.
1. Redundancy
Do not rely on a single instance of anything important.
If one node fails, another should take over. If one availability zone fails, traffic should route elsewhere. If one dependency is slow, the user journey should not collapse entirely.
2. Isolation
Failures should be contained.
Bulkheads prevent one failing part of the system from consuming every shared resource. If recommendations fail, checkout should still work. If analytics is delayed, authorisation should still proceed. If a downstream provider slows down, your thread pools and connection pools should not be exhausted across the platform.
3. Graceful Degradation
Serve something useful, even when you cannot serve everything.
When a product image CDN fails, show the page without images. When recommendations time out, show popular items. When a fraud-scoring service is degraded, route only higher-risk transactions for manual review and allow low-risk flows through defined rules.
4. Fast Recovery
Detect quickly, recover safely, and learn permanently.
Health checks, auto-scaling, deployment rollback, queue replay, regional failover, and incident runbooks reduce the time between “something is wrong” and “the system is stable again.”
Failure Modes To Design For
| Failure mode | What it looks like | Control |
|---|---|---|
| Slow dependency | Requests hang and threads pile up. | Timeouts, circuit breakers, and fallback responses. |
| Retry storm | Clients repeatedly hammer a failing service. | Exponential backoff, jitter, rate limits, and retry budgets. |
| Queue buildup | Consumers fall behind while producers keep publishing. | Lag alerts, autoscaling consumers, dead-letter queues, and replay tools. |
| Partial regional outage | One region is degraded but not completely down. | Health-based routing, synthetic checks, and clear failover criteria. |
| Database saturation | Latency rises before hard failure. | Connection limits, read replicas, caching, query budgets, and load shedding. |
| Bad deployment | A release introduces errors under real load. | Progressive delivery, canaries, automated rollback, and feature flags. |
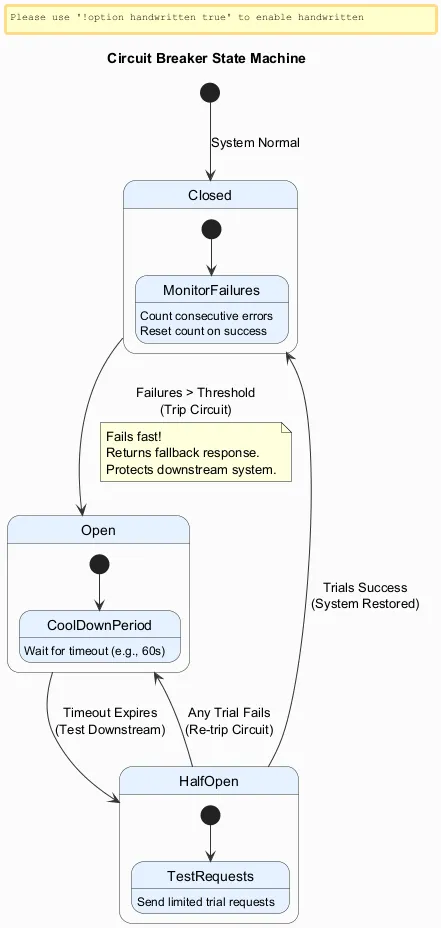
Circuit Breakers: The Pattern Most Teams Need Earlier
The circuit breaker pattern prevents a failing downstream service from taking down its callers.
It has three states:
| State | What happens | Why it matters |
|---|---|---|
| Closed | Requests flow normally while failures are counted. | The system behaves as expected. |
| Open | Calls fail fast and use a fallback after failures pass a threshold. | The failing dependency is protected and callers do not pile up. |
| Half-open | A small number of test calls are allowed after a cool-down period. | The system can recover without stampeding the dependency. |
On AWS, you might implement circuit breakers in application code, through service mesh patterns with Envoy/App Mesh, or at API boundaries with cached fallback responses.
On GCP, you might use application libraries, service mesh on GKE, Traffic Director patterns, or Cloud Run request concurrency and timeout controls as part of the containment strategy.
The platform matters less than the discipline: every external call needs a timeout, a retry policy, a fallback decision, and an owner.
AWS And GCP Resilience Patterns
| Need | AWS pattern | GCP pattern |
|---|---|---|
| Regional routing | Route 53 health checks, Global Accelerator, multi-region load balancing patterns. | Global external Application Load Balancer with regional backends. |
| Multi-region data | DynamoDB Global Tables, S3 replication, Aurora Global Database depending on consistency needs. | Cloud Spanner, multi-region Cloud Storage, Firestore multi-region options. |
| Async buffering | SQS, SNS, EventBridge, Kinesis. | Pub/Sub, Eventarc, Cloud Tasks, Dataflow. |
| Container recovery | ECS/Fargate service health, EKS, Auto Scaling Groups. | Cloud Run autoscaling, GKE, Managed Instance Groups. |
| Failure testing | AWS Fault Injection Service. | Litmus, Gremlin, k6/Locust, and GKE-based chaos tooling. |
The practical difference is that AWS often gives you many specialised building blocks and precise control. GCP often gives you more global primitives and a simpler developer path.
Neither removes the need to design the failure mode.
Multi-Region Is Not A Checkbox
Multi-region architecture is useful only when the team understands the trade-offs.
| Question | Why it matters |
|---|---|
| What is the recovery time objective? | Determines whether failover must be automatic or manual. |
| What is the recovery point objective? | Determines how much data loss, if any, is acceptable. |
| Is the system active-active or active-passive? | Changes complexity, cost, routing, data consistency, and testing. |
| How is data conflict handled? | Multi-region writes can create business-level conflicts. |
| How often is failover tested? | Untested failover is theatre. |
For payment-like systems, multi-region design is often necessary. But the harder part is not deploying twice. It is proving that failover, replay, reconciliation, and customer communication work under stress.
Health Checks That Actually Help
Not all health checks should do the same job.
| Health check | Purpose | Example |
|---|---|---|
| Shallow | Tell a load balancer the process is alive. | Return 200 if the app process can accept requests. |
| Deep | Prove the service can perform its core function. | Check database, cache, queue, and critical downstream dependencies. |
| Synthetic | Test a real user journey from outside. | Run a small end-to-end transaction or read path. |
| Deployment gate | Stop bad releases before rollout. | Run smoke tests, schema checks, and dependency checks before promotion. |
Use shallow checks for fast routing decisions.
Use deeper checks for operational confidence.
Chaos Engineering Without Theatre
Chaos engineering is not about breaking production for drama.
It is about discovering failure modes under controlled conditions before customers discover them for you.
Start small:
- Define the steady state. What should remain true during the experiment?
- Pick one failure. Kill one container, delay one dependency, fill one queue, or block one network path.
- Run it in staging first.
- Observe whether alerts, dashboards, runbooks, and fallbacks work.
- Turn the lesson into a permanent improvement.
The best chaos experiments are boring because the team already knows what should happen.
The Production Checklist
Every serious cloud system should have:
- health checks on every service
- timeouts on every network request
- retries with exponential backoff and jitter
- circuit breakers on external calls
- bulkheads around critical resources
- dead-letter queues for failed async work
- correlation IDs across request and event flows
- customer-impacting SLOs
- dashboards that show saturation, lag, error rate, latency, and business impact
- rollback and replay procedures
- incident runbooks that have been practiced
Security And Well-Architected Gaps To Call Out
Resilience work can accidentally focus only on uptime. That is too narrow. A system that stays online while leaking data, hiding incidents, or burning unlimited cost is not resilient in the Well-Architected sense.
| Gap | Why it matters | What to check |
|---|---|---|
| Weak identity boundaries | Failover and emergency access often bypass least privilege. | Break-glass access, IAM scope, service identities, and audit trails. |
| Missing data protection in recovery paths | Backups, replicas, logs, and dead-letter queues may contain sensitive data. | Encryption, retention, access controls, masking, and restore testing. |
| No incident response design | Teams detect failure but do not know who decides, communicates, or rolls back. | Runbooks, severity model, escalation paths, and customer communication templates. |
| Reliability without cost guardrails | Active-active and retries can create runaway spend during incidents. | Retry budgets, autoscaling limits, cost alerts, and failover cost models. |
| Observability gaps | Dashboards show infrastructure health but not customer impact. | SLOs, business metrics, synthetic checks, queue lag, and error budgets. |
| Untested recovery | Multi-region and backup designs exist only in diagrams. | Scheduled restore tests, failover game days, and evidence from last test. |
Use the AWS Well-Architected pillars as a forcing function: operational excellence, security, reliability, performance efficiency, cost optimization, and sustainability all matter during failure. Google Cloud’s framework makes the same point through operations, security, reliability, performance, and cost. A recovery design should be reviewed across all of them.
The Real Point
Resilience is not an infrastructure feature you add at the end.
It is a product quality.
The cloud gives you powerful primitives, but primitives do not make a system resilient by themselves. Resilience appears when teams design for failure, practice recovery, and keep improving the controls after every incident.
Start with the basics: timeouts, health checks, circuit breakers, and queues.
Then build toward multi-region, chaos testing, and automated recovery as the business need grows.
The cost of resilience is visible.
The cost of discovering you do not have it is much higher.
Sources and Further Reading
Written by Haris Habib from Sydney, Australia | February 2026