The mistake. Pick the smartest model. Send everything to it. Pay premium prices to summarise an email. There is a better way, and it is not complicated.
The Single-Model Trap
When people wire up an AI agent, they usually choose one model — normally the most capable one they can afford — and route every task through it.
It feels right. Smartest model, best results.
It is also how you end up paying flagship prices to do a job a cheap model does just as well: extracting a date from an email, deciding which tool to call, summarising a meeting note.
I run a self-hosted agent that does dozens of tasks a day — morning briefings, code edits, research summaries, market analysis. Routing all of that through one model would be slow and expensive. So it does not. It runs a multi-model architecture: different jobs go to different models, deliberately.
1. The Three Jobs Inside Every Agent
Almost everything an agent does falls into one of three buckets. Each wants a different kind of model.
| Job | What it looks like | What it needs |
|---|---|---|
| Orchestration | Routing, tool calls, “which step next?”, summarising | Fast, cheap, reliable — runs constantly |
| Execution | Writing code, scripts, automation, transforms | High throughput, strong at structure |
| Reasoning | Analysis, hard trade-offs, curated reports | Depth and accuracy, used sparingly |
The orchestrator is the dispatcher. It runs on almost every turn, so it must be cheap and fast. The reasoning model is the senior specialist — expensive, slow, and worth every cent on the 10% of tasks that actually need it.
Using your reasoning model as your dispatcher is like having a partner at a law firm answer the front desk phone.
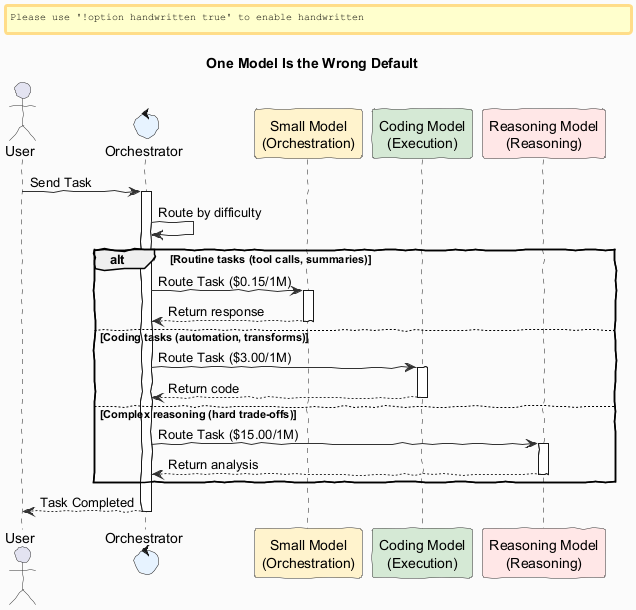
2. How My Agent Routes Work
The actual routing in my agent looks like this:
TASK MODEL TIER
──── ──────────
Tool calls / routing → small, fast orchestrator
Summarise / extract → small, fast orchestrator
Code / scripting → high-throughput coding model
Complex analysis → reasoning model (used rarely)
Huge context (>64k) → large-context model
A lightweight model handles orchestration and summarisation — the constant background hum. A high-throughput model handles coding and automation, where volume matters more than brilliance. A dedicated reasoning model is reserved for the genuinely hard calls: a market analysis, a trade-off with real consequences, a report someone will act on.
The orchestrator decides, per task, who gets the work.
3. The Cost Argument Is Brutal
This is not a marginal optimisation. The price gap between model tiers is often 10x to 30x+ per token:
| Tier / Model | Input Cost (per 1M tokens) | Output Cost (per 1M tokens) | Relative Price Difference |
|---|---|---|---|
| Reasoning Tier (e.g. OpenAI o1) | $15.00 | $60.00 | 100x (Reasoning vs. Small) |
| Execution / Coding (e.g. GPT-4o / Claude 3.5 Sonnet) | $2.50–$3.00 | $10.00–$15.00 | 16x–20x (Execution vs. Small) |
| Orchestration (e.g. GPT-4o-mini / Gemini 1.5 Flash) | $0.15 | $0.60 | Baseline (1x) |
SINGLE FLAGSHIP MODEL ROUTED MULTI-MODEL
───────────────────── ──────────────────
Every task at premium → Premium only when needed
Summary = flagship price → Summary = cents
1 model, 1 failure mode → Fallbacks across providers
Cost scales with activity → Cost scales with difficultyWhen you route by difficulty instead of sending everything to the top tier, the cheap tasks — which are most of them — cost almost nothing. Your spend tracks how hard the work was, not how much of it there was. For an always-on agent doing hundreds of small tasks a day, that is the difference between a hobby and a runaway bill.
4. Resilience Comes Free
There is a second prize beyond cost.
A single-model agent has a single point of failure. When that provider has an outage, rate-limits you, or quietly changes behaviour, your entire agent degrades at once.
A multi-model agent routes around trouble. If the coding model is down, automation can fall back to another. If one provider rate-limits, the orchestrator shifts load. You have already done the integration work to talk to several models — so a provider going dark becomes an inconvenience, not an outage.
In production, “it still works when one vendor breaks” is not a luxury. It is the baseline.
5. The Discipline Is the Moat
I have written before that in regulated AI, the moat is no longer the model — it is the discipline around the model. Routing is that idea made concrete.
| Anyone can do | Few actually do |
|---|---|
| Call the best model | Know which model each task deserves |
| Pay the bill | Engineer the bill down 10x |
| Hope the provider stays up | Build fallbacks before they are needed |
| Demo on one model | Run a fleet in production |
The teams that win the next phase of AI are not the ones with access to the best model. Everyone has that. They are the ones who built the routing layer — the judgement about which model to trust with what, at what cost, with what fallback.
The Big Takeaway
You would not hire one person to be your CFO, your developer, and your receptionist. Stop asking one model to be all three. Route by difficulty, pay by difficulty, and survive a provider outage while you are at it.
One model is the wrong default. The right default is a small, fast orchestrator that knows when to call in someone smarter — and a bill that proves it.
Related reading
- Your AI Agent Needs a Soul File — the memory layer that pairs with this routing layer.
- I Gave an AI Agent the Keys to My Life. Here Is the Trust Architecture. — the safety layer on top.
- MCP Tool Poisoning: The Attack Vector Nobody Is Talking About — why discipline beats raw capability.
- The 10-Star Experience: Why Product and Engineering Need Legendary Test Cases — how routing to the right model enables a seamless, fast 10-star experience.
Written by Haris Habib from Sydney, Australia | May 2026