Event-driven architecture is one of the most useful patterns in distributed systems.
It is also one of the easiest to misuse.
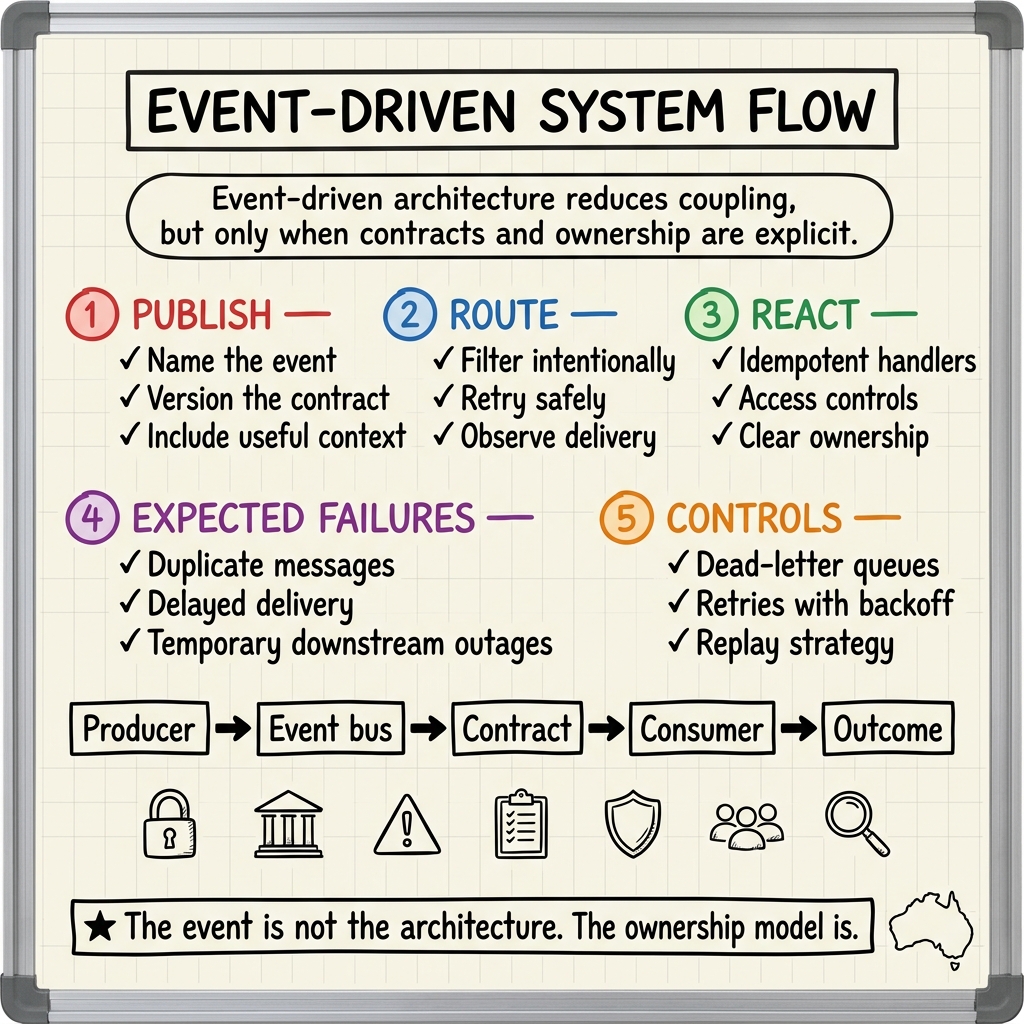
The promise is simple: instead of services calling each other directly and creating brittle chains of dependency, services publish events: facts about something that happened. Other services react asynchronously.
The trap is thinking the event bus is the architecture.
It is not.
The real architecture is the ownership model, event contract, failure handling, replay strategy, and operational visibility around the event bus.
Why Event-Driven Systems Matter
Traditional request-response systems create tight coupling. Service A calls Service B, which calls Service C. When Service C is slow, everything upstream waits. When Service C fails, upstream services fail too.
Event-driven systems break that chain.
| Benefit | What it gives you | Hidden responsibility |
|---|---|---|
| Loose coupling | Producers do not need to know every consumer. | Event contracts must be stable and versioned. |
| Resilience | Consumers can fail without blocking producers. | Retries, dead-letter queues, and replay must be designed. |
| Scalability | Producers and consumers scale independently. | Backpressure, lag, and duplicate handling must be monitored. |
| Auditability | Events record business facts over time. | Correlation IDs and retention rules must be consistent. |
| Extensibility | New consumers can react to existing events. | Ownership must prevent event sprawl and unclear semantics. |
In payments, this is not optional. Authorisation, fraud scoring, customer notification, clearing, settlement, reconciliation, and reporting all involve state changes that need to be recorded and reacted to safely.
Start With The Event Contract
Before choosing EventBridge or Pub/Sub, define the event.
A good event is a business fact, not an implementation detail.
| Weak event | Better event | Why |
|---|---|---|
DatabaseRowUpdated | PaymentAuthorised | Consumers should react to business meaning, not storage mechanics. |
UserChanged | CustomerAddressUpdated | Specific events reduce ambiguity. |
StatusChanged | RefundApproved | The event name should explain what happened. |
ProcessFinished | SettlementFileGenerated | Business language improves ownership and auditability. |
A production event should usually include:
- event name
- event version
- event ID
- occurred-at timestamp
- producer name
- correlation ID or trace ID
- aggregate/entity ID
- business payload
- schema reference
- privacy classification where relevant
AWS: The EventBridge Advantage
AWS has one of the most complete event-driven ecosystems in the cloud, especially when centred around Amazon EventBridge.
| AWS service | Role | Best fit |
|---|---|---|
| EventBridge | Event bus, routing rules, partner events, schema registry patterns. | Complex routing, multi-account events, integration-heavy systems. |
| SQS | Durable queue with retries and dead-letter queues. | Buffering, decoupling, controlled consumer processing. |
| SNS | Pub/sub fan-out. | Notification-style fan-out and broad distribution. |
| Kinesis | Ordered streaming at high throughput. | Real-time analytics, stream processing, ordered event streams. |
| Lambda | Serverless event processing. | Lightweight handlers and glue logic. |
| Step Functions | Workflow orchestration. | Sagas, stateful processes, compensation logic. |
Pattern: Domain Event Fan-Out
When a payment is processed, multiple services may need to react: fraud review, notification, analytics, reconciliation, and settlement.
On AWS:
- The payment service publishes
PaymentProcessedto EventBridge. - EventBridge routes events by content and rule.
- High-risk payments go to an SQS fraud queue.
- International payments trigger compliance processing.
- All payment events flow into analytics.
- Each consumer processes independently and owns its own retries.
EventBridge’s content-based routing is valuable because routing logic can be declarative rather than buried inside one central orchestrator.
Pattern: Saga Orchestration
For long-running workflows, Step Functions can coordinate the process.
A refund might need to update payment state, inventory, customer notification, loyalty points, and ledger entries. If one step fails, compensating actions may be required.
Step Functions gives operators a visible execution history. That visibility is not a nice-to-have. It is what makes a failed distributed workflow diagnosable.
GCP: Pub/Sub, Eventarc, And Cloud Run
GCP takes a simpler and more developer-friendly approach, with strong support for containers and open event standards.
| GCP service | Role | Best fit |
|---|---|---|
| Pub/Sub | Global messaging service. | High-throughput async communication and fan-out. |
| Eventarc | Event routing using CloudEvents. | Routing Google Cloud and custom events to Cloud Run and other targets. |
| Cloud Run | Serverless container runtime. | Event handlers that need container flexibility and simple operations. |
| Cloud Functions | Lightweight event processing. | Small, focused functions. |
| Dataflow | Apache Beam stream processing. | Streaming analytics, enrichment, and complex data pipelines. |
| Workflows | Managed workflow orchestration. | API orchestration and step-based business processes. |
Pattern: Pub/Sub Fan-Out
On GCP:
- The payment service publishes
PaymentProcessedto a Pub/Sub topic. - Multiple subscriptions deliver the event to different consumers.
- A Cloud Run fraud service processes one subscription.
- A Cloud Functions notification handler processes another.
- Dataflow consumes another stream for analytics.
Each subscription has its own retry and acknowledgement lifecycle. That is a clean model for independent consumers.
The main difference from EventBridge is routing. Pub/Sub is excellent at delivery and scale, but content-based routing usually requires topic design, filters, Eventarc, or logic in the consumer.
Pattern: Eventarc + Cloud Run
Eventarc shines when you want cloud events delivered into containerised services.
For example, a file upload to Cloud Storage can trigger Eventarc, which delivers a CloudEvents-formatted event to Cloud Run. Cloud Run processes the file, writes metadata, and publishes a result to Pub/Sub.
CloudEvents is valuable because it gives teams a standard event envelope instead of a platform-specific shape.
AWS vs GCP: The Decision Table
| Decision area | AWS is stronger when… | GCP is stronger when… |
|---|---|---|
| Event routing | You need rich routing rules and multi-account event patterns. | You prefer simpler topic/subscription designs and Cloud Run targets. |
| Developer experience | Your team already works deeply in AWS patterns. | Your team values Cloud Run, containers, and simpler deployment. |
| Streaming analytics | You need Kinesis-native AWS integration. | You want Dataflow/Apache Beam and BigQuery integration. |
| Workflow orchestration | You need mature saga visibility with Step Functions. | You need lighter API orchestration with Workflows. |
| Open standards | Platform-native AWS integration is more important. | CloudEvents portability matters. |
| Operations | You want many specialised controls. | You want fewer primitives with global defaults. |
The right choice depends less on the service names and more on your operating constraints.
The Failure Handling Checklist
An event-driven system is not production-ready until it answers these questions:
| Question | Why it matters |
|---|---|
| Are consumers idempotent? | Events may be delivered more than once. |
| What happens after repeated failure? | Dead-letter queues must be monitored and owned. |
| Can events be replayed? | Recovery often requires reprocessing historical events. |
| How are schemas versioned? | Producers and consumers evolve at different speeds. |
| How is ordering handled? | Some workflows require per-entity ordering. |
| How is correlation tracked? | Operators need to reconstruct the business journey. |
| Who owns each event? | Without ownership, contracts decay. |
Security And Well-Architected Gaps To Call Out
Event-driven systems often fail quietly because the failure is spread across producers, brokers, consumers, queues, and dashboards.
| Gap | What it looks like | Control |
|---|---|---|
| Over-shared event payloads | Events include customer data, payment data, secrets, or internal-only fields that every subscriber can read. | Minimise payloads, classify data, encrypt where needed, and use claim-check patterns for sensitive detail. |
| Weak producer identity | Any service can publish trusted business events. | Authenticate producers, authorise event sources, and monitor unexpected publishers. |
| Uncontrolled consumers | New subscribers consume events without business owner approval. | Subscription approval, data contracts, and access review. |
| Schema drift | Producers change payloads and consumers fail later. | Versioned schemas, compatibility checks, contract tests, and deprecation policy. |
| Dead-letter blind spots | Failed events pile up without alerting or ownership. | DLQ dashboards, alerts, runbooks, replay tools, and named owners. |
| Replay risk | Reprocessing old events triggers duplicate customer actions. | Idempotency keys, action guards, replay modes, and dry-run tooling. |
The Well-Architected gap is usually operational excellence plus security. A good event platform should make ownership, contracts, failure, replay, cost, and access visible. If the team cannot answer who owns an event and what happens when it fails, the architecture is not ready.
Getting Started
Start small.
- Pick one synchronous integration that causes coupling or reliability pain.
- Define the business event in domain language.
- Create the event contract and owner.
- Publish the event from the source service.
- Add one consumer.
- Add retry, dead-letter, alerting, and replay from day one.
- Measure latency, lag, failure rate, and business outcome.
Do not event-source your whole company because a diagram looked elegant.
Use events where they reduce coupling, improve resilience, create useful audit history, or allow independent services to react to business facts.
The Real Lesson
Event-driven architecture is not about making everything asynchronous.
It is about making business change visible, durable, and safely consumable by the rest of the system.
AWS gives you powerful routing and workflow primitives. GCP gives you clean global messaging, Cloud Run simplicity, and open event standards.
Both can work well.
Both can become chaos.
The difference is whether your events have clear meaning, ownership, contracts, recovery paths, and observability.
Sources and Further Reading
Written by Haris Habib from Sydney, Australia | February 2026